Nội Dung
Giới thiệu
Bất kỳ ứng dụng hoặc trang web nào có sự tăng trưởng đáng kể, cuối cùng đều cần phải mở rộng quy mô để phù hợp với sự gia tăng lưu lượng. Đối với các ứng dụng và trang web có nhiều dữ liệu, điều quan trọng là việc chia tỷ lệ được thực hiện theo cách đảm bảo tính bảo mật và tính toàn vẹn của dữ liệu của dữ liệu. Có thể khó dự đoán mức độ phổ biến của một trang web hoặc ứng dụng hoặc thời gian duy trì mức độ phổ biến đó, đó là lý do tại sao một số tổ chức chọn kiến trúc cơ sở dữ liệu cho phép họ mở rộng quy mô cơ sở dữ liệu của họ một cách linh hoạt.
Trong bài viết khái niệm này, chúng ta sẽ thảo luận về một kiến trúc cơ sở dữ liệu như vậy: cơ sở dữ liệu phân đoạn (Sharding). Sharding đã nhận được rất nhiều sự chú ý trong những năm gần đây, nhưng nhiều người không có sự hiểu biết rõ ràng về nó là gì hoặc các kịch bản trong đó việc sharding dữ liệu trở nên có ý nghĩa. Chúng ta sẽ tìm hiểu xem sharding là gì, một số lợi ích và nhược điểm chính của nó, và một vài phương pháp sharding phổ biến.
Bạn đang xem: Database sharding là gì?
Vậy sharding là gì?
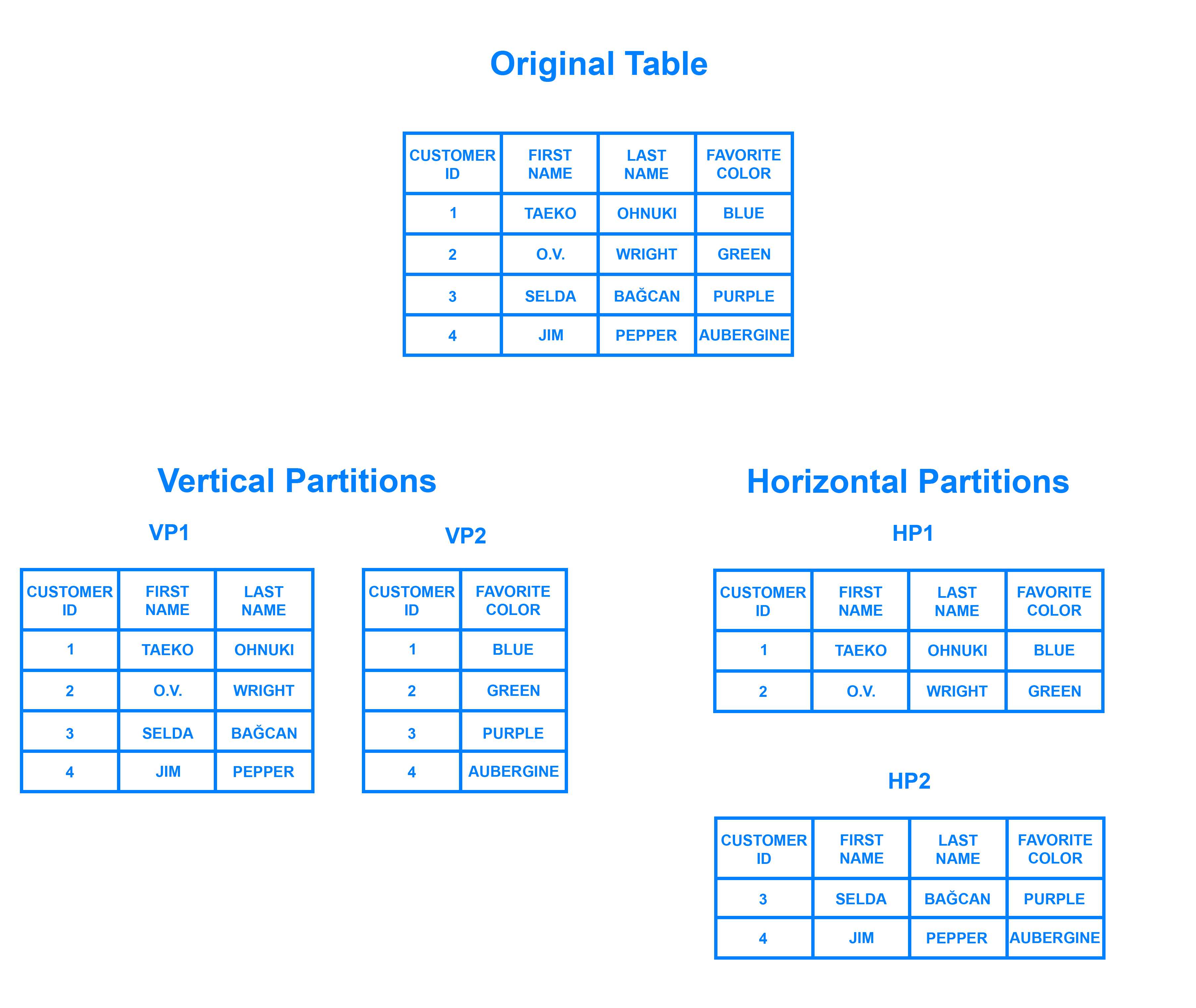
Sharding là một mẫu kiến trúc cơ sở dữ liệu liên quan đến phân vùng ngang – thực tế tách một hàng bảng Bảng thành nhiều bảng khác nhau, được gọi là partitions. Mỗi partitions có cùng schema và cột, nhưng cũng có các hàng hoàn toàn khác nhau. Tương tự, dữ liệu được giữ trong mỗi partitions là duy nhất và độc lập với dữ liệu được giữ trong các partitions khác.
Có thể hữu ích khi so sánh suy nghĩ về phân vùng ngang theo cách nó liên quan đến phân vùng dọc. Trong một bảng được phân vùng theo chiều dọc, toàn bộ các cột được tách ra và đưa vào các bảng mới, riêng biệt. Dữ liệu được giữ trong một phân vùng dọc độc lập với dữ liệu trong tất cả các phân vùng khác và mỗi dữ liệu chứa cả các hàng và cột riêng biệt. Sơ đồ sau minh họa cách bảng có thể được phân vùng theo cả chiều ngang và chiều dọc:

Sharding liên quan đến việc chia một dữ liệu thành hai hoặc nhiều phần nhỏ hơn, được gọi là logical shard (phân đoạn logic). Các logical shard sau đó được phân phối trên các database node riêng biệt, được gọi là các physical shard (phân đoạn vật lý), có thể chứa nhiều logical shard. Mặc dù vậy, dữ liệu được lưu giữ trong tất cả các phân đoạn chung đại diện cho toàn bộ dữ liệu logic.
Phân đoạn cơ sở dữ liệu minh họa một kiến trúc không chia sẻ. Điều này có nghĩa là các shard là tự trị; họ không chia sẻ bất kỳ tài nguyên dữ liệu hoặc tài nguyên máy tính nào. Tuy nhiên, trong một số trường hợp, có thể có ý nghĩa khi sao chép một số bảng nhất định vào từng shard để phục vụ như các bảng tham chiếu. Ví dụ: giả sử, có một cơ sở dữ liệu cho một ứng dụng phụ thuộc vào tỷ lệ chuyển đổi cố định cho các phép đo trọng lượng. Bằng cách sao chép một bảng chứa dữ liệu tỷ lệ chuyển đổi cần thiết vào từng phân đoạn, sẽ giúp đảm bảo rằng tất cả dữ liệu cần thiết cho các truy vấn được giữ trong mỗi phân đoạn.
Thông thường, sharding được triển khai ở cấp ứng dụng, nghĩa là ứng dụng bao gồm mã xác định shard nào sẽ truyền đọc và ghi vào. Tuy nhiên, một số hệ thống quản lý cơ sở dữ liệu có các khả năng tích hợp sẵn tính năng sharding, bạn có thể triển khai sharding trực tiếp ở cấp cơ sở dữ liệu.
Đưa ra cái nhìn tổng quan chung về sharding, hãy để Lướt qua một số điểm tích cực và tiêu cực liên quan đến kiến trúc cơ sở dữ liệu này.
Lợi ích của Sharding
Sự hấp dẫn chính của việc bảo vệ cơ sở dữ liệu là nó có thể giúp tạo điều kiện mở rộng theo chiều ngang, còn được gọi là nhân rộng. Chia tỷ lệ theo chiều ngang là cách thực hành thêm nhiều máy vào ngăn xếp hiện có để phân tán tải và cho phép lưu lượng truy cập nhiều hơn và xử lý nhanh hơn. Điều này thường tương phản với tỷ lệ dọc, còn được gọi là nhân rộng, liên quan đến việc nâng cấp phần cứng của máy chủ hiện có, thường bằng cách thêm nhiều RAM hoặc CPU.
Nó tương đối đơn giản để có một cơ sở dữ liệu quan hệ chạy trên một máy duy nhất và mở rộng nó khi cần thiết bằng cách nâng cấp tài nguyên máy tính của nó. Cuối cùng, mặc dù, bất kỳ cơ sở dữ liệu không phân tán nào cũng sẽ bị giới hạn về lưu trữ và khả năng tính toán, do đó, có quyền tự do mở rộng theo chiều ngang giúp thiết lập của bạn linh hoạt hơn rất nhiều.
Một lý do khác khiến một số người có thể chọn kiến trúc cơ sở dữ liệu bị phân mảnh là để tăng tốc thời gian phản hồi truy vấn. Khi bạn gửi một truy vấn trên cơ sở dữ liệu đã bị hủy, nó có thể phải tìm kiếm mọi hàng trong bảng mà bạn truy vấn trước khi nó có thể tìm thấy kết quả mà bạn đang tìm kiếm. Đối với một ứng dụng có cơ sở dữ liệu lớn, nguyên khối, các truy vấn có thể trở nên chậm chạp. Tuy nhiên, bằng cách chia một bảng thành nhiều bảng, các truy vấn phải đi qua ít hàng hơn và các tập kết quả của chúng được trả về nhanh hơn nhiều.
Shending cũng có thể giúp làm cho một ứng dụng đáng tin cậy hơn bằng cách giảm thiểu tác động của việc ngừng hoạt động. Nếu ứng dụng hoặc trang web của bạn dựa trên cơ sở dữ liệu không được bảo vệ, việc ngừng hoạt động có khả năng khiến toàn bộ ứng dụng không khả dụng. Tuy nhiên, với một cơ sở dữ liệu được phân chia, việc ngừng hoạt động có khả năng chỉ ảnh hưởng đến một phân đoạn duy nhất. Mặc dù điều này có thể làm cho một số phần của ứng dụng hoặc trang web không khả dụng đối với một số người dùng, tác động tổng thể vẫn sẽ ít hơn nếu toàn bộ cơ sở dữ liệu bị sập.
Hạn chế của Sharding
Xem thêm : Pay Back là gì và cấu trúc cụm từ Pay Back trong câu Tiếng Anh
Mặc dù việc bảo vệ cơ sở dữ liệu có thể giúp mở rộng quy mô dễ dàng hơn và cải thiện hiệu suất, nhưng nó cũng có thể áp đặt một số hạn chế nhất định. Ở đây, chúng tôi sẽ thảo luận về một số trong số này và tại sao chúng có thể là lý do để tránh hoàn toàn.
Khó khăn đầu tiên mà mọi người gặp phải với shending là sự phức tạp tuyệt đối của việc thực hiện đúng một kiến trúc cơ sở dữ liệu bị phân mảnh. Nếu được thực hiện không chính xác, có một rủi ro đáng kể rằng quá trình shending có thể dẫn đến mất dữ liệu hoặc các bảng bị hỏng. Tuy nhiên, ngay cả khi được thực hiện một cách chính xác, việc bảo vệ có thể có tác động lớn đến quy trình làm việc nhóm của bạn. Thay vì truy cập và quản lý một dữ liệu từ một điểm nhập cảnh duy nhất, người dùng phải quản lý dữ liệu trên nhiều vị trí phân đoạn, điều này có khả năng gây gián đoạn cho một số nhóm.
Một vấn đề mà người dùng đôi khi gặp phải sau khi hủy cơ sở dữ liệu là các mảnh vỡ cuối cùng trở nên mất cân bằng. Ví dụ, giả sử bạn có một cơ sở dữ liệu với hai phân đoạn riêng biệt, một cho khách hàng có họ bắt đầu bằng chữ A đến M và một cho những người có tên bắt đầu bằng chữ N đến Z. Tuy nhiên, ứng dụng của bạn phục vụ số lượng không phù hợp trong số những người có họ bắt đầu bằng chữ G. Theo đó, phân đoạn AM tích lũy dần dữ liệu hơn so với người New Zealand, khiến ứng dụng bị chậm lại và bị đình trệ trong một phần đáng kể người dùng của bạn. Phân đoạn A-M đã trở thành điểm được gọi là điểm nóng cơ sở dữ liệu. Trong trường hợp này, bất kỳ lợi ích nào của việc bảo vệ cơ sở dữ liệu sẽ bị hủy bỏ do sự chậm lại và sự cố. Cơ sở dữ liệu có thể sẽ cần phải được sửa chữa và định hình lại để cho phép phân phối dữ liệu đồng đều hơn.
Một nhược điểm lớn khác là một khi cơ sở dữ liệu đã bị hủy, có thể rất khó để đưa nó trở lại kiến trúc không bị che chắn. Bất kỳ bản sao lưu nào của cơ sở dữ liệu được thực hiện trước khi nó bị hủy bỏ sẽ bao gồm dữ liệu được ghi từ khi phân vùng. Do đó, việc xây dựng lại kiến trúc không có bản gốc sẽ yêu cầu hợp nhất dữ liệu được phân vùng mới với các bản sao lưu cũ hoặc, thay vào đó, chuyển đổi DB được phân vùng trở lại thành một DB duy nhất, cả hai đều tốn kém và mất thời gian.
Một nhược điểm cuối cùng cần xem xét là việc shending isn được hỗ trợ bởi mọi công cụ cơ sở dữ liệu. Chẳng hạn, PostgreSQL không bao gồm tính năng tự động tắt như một tính năng, mặc dù có thể tự hủy cơ sở dữ liệu PostgreQuery. Có một số nhánh Postgres bao gồm shending tự động, nhưng chúng thường đi sau bản phát hành PostgreQuery mới nhất và thiếu một số tính năng khác. Một số công nghệ cơ sở dữ liệu chuyên dụng – như MySQL Cluster hoặc một số sản phẩm dịch vụ cơ sở dữ liệu nhất định như MongoDB Atlas – bao gồm tự động tắt như một tính năng, nhưng các phiên bản vanilla của các hệ thống quản lý cơ sở dữ liệu này thì không. Bởi vì điều này, shending thường đòi hỏi một cách tiếp cận của riêng bạn. Điều này có nghĩa là tài liệu về shending hoặc mẹo khắc phục sự cố thường khó tìm.
Tất nhiên, đây chỉ là một số vấn đề chung cần xem xét trước khi bảo vệ. Có thể có nhiều nhược điểm tiềm năng hơn trong việc bảo vệ cơ sở dữ liệu tùy thuộc vào trường hợp sử dụng.
Bây giờ, chúng tôi đã đề cập đến một số hạn chế và lợi ích của Shending, chúng tôi sẽ giới thiệu một vài kiến trúc khác nhau cho các cơ sở dữ liệu được phân chia.
Các kiến trúc Sharding
Key Based Sharding
Sharding dựa trên khóa, còn được gọi là sharding dựa trên băm, liên quan đến việc sử dụng một giá trị được lấy từ dữ liệu mới được viết – chẳng hạn như số ID của khách hàng, địa chỉ IP của ứng dụng khách, mã ZIP, v.v. – và cắm nó vào hàm băm để xác định mà shard dữ liệu nên đi đến. Hàm băm là một hàm lấy đầu vào là một phần dữ liệu (ví dụ: email của khách hàng) và xuất ra một giá trị riêng biệt, được gọi là giá trị băm. Trong trường hợp sharding, giá trị băm là ID shard được sử dụng để xác định phân đoạn nào dữ liệu đến sẽ được lưu trữ trên đó. Nhìn chung, quá trình này trông như thế này:
Để đảm bảo rằng các mục được đặt trong các phân đoạn chính xác và theo cách nhất quán, tất cả các giá trị được nhập vào hàm băm phải xuất phát từ cùng một cột. Cột này được gọi là một khóa shard. Nói một cách đơn giản, các khóa shard tương tự như các khóa chính ở cả hai đều là các cột được sử dụng để thiết lập một mã định danh duy nhất cho các hàng riêng lẻ. Nói rộng ra, một khóa shard phải là tĩnh, có nghĩa là nó không nên chứa các giá trị có thể thay đổi theo thời gian. Mặt khác, nó sẽ tăng số lượng công việc đi vào hoạt động cập nhật và có thể làm chậm hiệu suất.
Mặc dù shending dựa trên khóa là một kiến trúc sharding khá phổ biến, nó có thể khiến mọi thứ trở nên khó khăn khi cố gắng tự động thêm hoặc xóa các máy chủ bổ sung vào cơ sở dữ liệu. Khi bạn thêm máy chủ, mỗi máy chủ sẽ cần một giá trị băm tương ứng và nhiều mục nhập hiện có của bạn, nếu không phải tất cả chúng, sẽ cần được ánh xạ tới giá trị băm mới, chính xác của chúng và sau đó được di chuyển đến máy chủ phù hợp. Khi bạn bắt đầu cân bằng lại dữ liệu, các hàm băm mới và cũ đều không hợp lệ. Do đó, máy chủ của bạn đã giành chiến thắng có thể ghi bất kỳ dữ liệu mới nào trong quá trình di chuyển và ứng dụng của bạn có thể bị ngừng hoạt động.
Sự hấp dẫn chính của chiến lược này là nó có thể được sử dụng để phân phối dữ liệu đồng đều để ngăn chặn các điểm nóng. Ngoài ra, vì nó phân phối dữ liệu theo thuật toán, nên không cần duy trì bản đồ nơi chứa tất cả dữ liệu, điều cần thiết với các chiến lược khác như ngăn chặn dựa trên phạm vi hoặc thư mục.
Range Based Sharding
Sharding dựa trên phạm vi liên quan đến sharding dữ liệu dựa trên phạm vi của một giá trị nhất định. Để minh họa, hãy để nói rằng bạn có một cơ sở dữ liệu lưu trữ thông tin về tất cả các sản phẩm trong danh mục của nhà bán lẻ. Bạn có thể tạo một vài phân đoạn khác nhau và phân chia từng sản phẩm Thông tin trên mạng dựa trên phạm vi giá mà chúng rơi vào, như thế này:

Xem thêm : Cell pin laptop là gì? Có nên thay Cell pin cho Laptop không?
Lợi ích chính của sharding dựa trên phạm vi là nó thực hiện tương đối đơn giản. Mỗi phân đoạn chứa một tập hợp dữ liệu khác nhau nhưng tất cả chúng đều có một lược đồ giống hệt nhau, cũng như cơ sở dữ liệu gốc. Mã ứng dụng chỉ đọc phạm vi dữ liệu rơi vào và ghi nó vào phân đoạn tương ứng.
Mặt khác, sharding dựa trên phạm vi không bảo vệ dữ liệu khỏi bị phân phối không đồng đều, dẫn đến các điểm nóng cơ sở dữ liệu nói trên. Nhìn vào sơ đồ ví dụ, ngay cả khi mỗi phân đoạn chứa một lượng dữ liệu bằng nhau, tỷ lệ cược là các sản phẩm cụ thể sẽ nhận được nhiều sự chú ý hơn các sản phẩm khác. Lần lượt các mảnh tương ứng của họ sẽ nhận được số lần đọc không tương xứng.
Directory Based Sharding
Để thực hiện phân đoạn dựa trên thư mục, người ta phải tạo và duy trì bảng tra cứu sử dụng khóa phân đoạn để theo dõi phân đoạn nào chứa dữ liệu nào. Tóm lại, bảng tra cứu là bảng chứa một tập hợp thông tin tĩnh về nơi có thể tìm thấy dữ liệu cụ thể. Sơ đồ sau đây cho thấy một ví dụ đơn giản về sharding dựa trên thư mục

Ở đây, cột Vùng phân phối được xác định là khóa phân đoạn. Dữ liệu từ khóa shard được ghi vào bảng tra cứu cùng với bất kỳ phân đoạn nào mà mỗi hàng tương ứng sẽ được ghi vào. Điều này tương tự với phân đoạn dựa trên phạm vi, nhưng thay vì xác định phạm vi mà dữ liệu khóa shard rơi vào, mỗi khóa được gắn với phân đoạn cụ thể của chính nó. Sharding dựa trên thư mục là một lựa chọn tốt trong sharding dựa trên phạm vi trong trường hợp khóa shard có số lượng cardin thấp và nó không có ý nghĩa cho shard lưu trữ một loạt các khóa. Lưu ý rằng nó cũng khác biệt với sharding dựa trên khóa ở chỗ nó không xử lý khóa shard thông qua hàm băm; nó chỉ kiểm tra khóa dựa vào bảng tra cứu để xem dữ liệu cần ghi ở đâu.
Sự hấp dẫn chính của sharding dựa trên thư mục là tính linh hoạt của nó. Các kiến trúc sharding dựa trên phạm vi giới hạn bạn trong việc chỉ định phạm vi giá trị, trong khi các kiến trúc dựa trên khóa giới hạn bạn sử dụng hàm băm cố định, như đã đề cập trước đây, có thể cực kỳ khó thay đổi sau này. Mặt khác, sharding dựa trên thư mục cho phép bạn sử dụng bất kỳ hệ thống hoặc thuật toán nào bạn muốn gán các mục nhập dữ liệu cho các phân đoạn và nó tương đối dễ dàng để tự động thêm các phân đoạn bằng cách sử dụng phương pháp này.
Mặc dù sharding dựa trên thư mục là cách linh hoạt nhất trong các phương thức sharding được thảo luận ở đây, nhu cầu kết nối với bảng tra cứu trước mỗi truy vấn hoặc ghi có thể có tác động bất lợi đến hiệu suất của ứng dụng. Hơn nữa, bảng tra cứu có thể trở thành một điểm thất bại duy nhất: nếu nó bị hỏng hoặc thất bại, nó có thể ảnh hưởng đến khả năng của một người khác để ghi dữ liệu mới hoặc truy cập dữ liệu hiện có của họ.
Tôi có nên thực hiện sharding không?
Việc một người có nên thực hiện một kiến trúc cơ sở dữ liệu bị phân tách hay không hầu như luôn là vấn đề tranh luận. Một số người coi sharding là kết quả không thể tránh khỏi đối với các cơ sở dữ liệu đạt đến một kích thước nhất định, trong khi những người khác coi đó là vấn đề đau đầu nên tránh trừ khi nó hoàn toàn cần thiết, do sự phức tạp trong hoạt động mà sharding thêm vào.
Do sự phức tạp được thêm vào này, sharding thường chỉ được thực hiện khi xử lý một lượng dữ liệu rất lớn. Dưới đây là một số tình huống phổ biến trong đó có thể có ích để bảo vệ cơ sở dữ liệu:
- Lượng dữ liệu ứng dụng tăng lên vượt quá dung lượng lưu trữ của một nút cơ sở dữ liệu.
- Khối lượng ghi hoặc đọc vào cơ sở dữ liệu vượt quá những gì một nút hoặc bản sao đọc của nó có thể xử lý, dẫn đến thời gian phản hồi hoặc thời gian chờ bị chậm.
- Băng thông mạng được ứng dụng yêu cầu vượt quá băng thông có sẵn cho một nút cơ sở dữ liệu và bất kỳ bản sao đọc nào, dẫn đến thời gian phản hồi hoặc thời gian chờ bị chậm.
Trước khi sharding, bạn nên sử dụng tất cả các tùy chọn khác để tối ưu hóa cơ sở dữ liệu của bạn. Một số tối ưu hóa bạn có thể muốn xem xét bao gồm:
-** Thiết lập cơ sở dữ liệu từ xa.** Nếu bạn làm việc với một ứng dụng nguyên khối trong đó tất cả các thành phần của nó nằm trên cùng một máy chủ, bạn có thể cải thiện hiệu suất cơ sở dữ liệu của mình bằng cách chuyển nó sang máy của chính nó. Điều này không có thêm sự phức tạp như sharding vì các bảng cơ sở dữ liệu còn nguyên vẹn. Tuy nhiên, nó vẫn cho phép bạn mở rộng quy mô theo chiều dọc cơ sở dữ liệu của bạn ngoài phần còn lại của cơ sở hạ tầng.
- Thực hiện lưu trữ. Nếu ứng dụng của bạn, thì hiệu suất đọc của bạn là thứ khiến cho bạn gặp rắc rối, bộ nhớ đệm là một chiến lược có thể giúp cải thiện nó. Bộ nhớ đệm liên quan đến việc lưu trữ tạm thời dữ liệu đã được yêu cầu trong bộ nhớ, cho phép bạn truy cập dữ liệu nhanh hơn sau này.
- Tạo một hoặc nhiều bản sao đọc. Một chiến lược khác có thể giúp cải thiện hiệu suất đọc, điều này liên quan đến việc sao chép dữ liệu từ một máy chủ cơ sở dữ liệu (máy chủ chính) sang một hoặc nhiều máy chủ thứ cấp. Theo đó, mỗi lần ghi mới sẽ chuyển đến bản chính trước khi được sao chép sang phần thứ hai, trong khi các lần đọc được thực hiện riêng cho các máy chủ thứ cấp. Phân phối đọc và ghi như thế này giữ cho bất kỳ một máy nào không phải chịu quá nhiều tải, giúp ngăn chặn sự chậm lại và sự cố. Lưu ý rằng việc tạo các bản sao đọc liên quan đến nhiều tài nguyên máy tính hơn và do đó tốn nhiều tiền hơn, điều này có thể là một hạn chế đáng kể đối với một số người.
- Nâng cấp lên một máy chủ lớn hơn. Trong hầu hết các trường hợp, việc mở rộng một máy chủ cơ sở dữ liệu trên máy chủ thành một máy có nhiều tài nguyên hơn đòi hỏi ít nỗ lực hơn so với sharding. Cũng như việc tạo các bản sao đọc, một máy chủ được nâng cấp với nhiều tài nguyên hơn có thể sẽ tốn nhiều tiền hơn. Theo đó, bạn chỉ nên thực hiện thay đổi kích thước nếu nó thực sự là lựa chọn tốt nhất của bạn.
Hãy nhớ rằng nếu ứng dụng hoặc trang web của bạn phát triển vượt quá một điểm nhất định, không có chiến lược nào trong số những chiến lược này sẽ đủ để tự cải thiện hiệu suất. Trong những trường hợp như vậy, sharding thực sự có thể là lựa chọn tốt nhất cho bạn.
Kết luận
Sharding có thể là một giải pháp tuyệt vời cho những người muốn mở rộng quy mô cơ sở dữ liệu của họ theo chiều ngang. Tuy nhiên, nó cũng thêm rất nhiều phức tạp và tạo ra nhiều điểm thất bại tiềm năng cho ứng dụng của bạn. Sharding có thể cần thiết cho một số người, nhưng thời gian và tài nguyên cần thiết để tạo và duy trì một kiến trúc bị che khuất có thể vượt xa lợi ích cho những người khác.
Bằng cách đọc bài viết khái niệm này, bạn sẽ có một sự hiểu biết rõ ràng hơn về những ưu và nhược điểm của sharding. Tiến về phía trước, bạn có thể sử dụng thông tin chi tiết này để đưa ra quyết định sáng suốt hơn về việc liệu kiến trúc cơ sở dữ liệu được phân chia có phù hợp với ứng dụng của bạn hay không.
Tham khảo
Nguồn: https://25giay.vn
Danh mục: Hỏi Đáp