Lucene Core là một thư viện Java cung cấp các tính năng lập chỉ mục và tìm kiếm mạnh mẽ, cũng như kiểm tra chính tả và analysis/tokenization
- Entry level là gì? Doanh nghiệp có lợi thế gì khi tuyển dụng nhân sự vào vị trí Entry – level?
- NXTcoin là gì? Tìm hiểu về đồng tiền ảo NXT là gì?
- Patina là gì ? Tại sao giày da đánh màu đều gọi là Patina ?
- Trong Suốt trong Tiếng Anh là gì: Định Nghĩa, Ví Dụ Anh Việt
- Bạn đã biết CC và BCC trong gmail là gì? Cách gửi CC BCC
Nội Dung
Giới thiệu về Lucene
Lucene được phát triển bởi Dough Cutting vào tháng 8 năm 2000, hiện tại đang được Apache phát triển và hỗ trợ.
Bạn đang xem: Lucene là gì? Tìm hiểu về Lucene và Elasticsearch
Lucene là phần mềm mã nguồn mở, dùng để phân tích, đánh chỉ mục và tìm kiếm thông tin với hiệu suất cao bằng Java. Lucene được phát triển đầu tiên bởi Doug Cutting được giới thiệu đầu tiên vào tháng 8 năm 2000. Tháng 9 năm 2001 Lucene gia nhập vào tổ chức Apache và hiện tại được Apache phát triển và quản lý. Cần lưu ý rằng Lucene không phải là một ứng dụng mà chỉ là một công cụ đặc tả API cần thiết cho việc một search engine.
Lucene hỗ trợ cho việc đánh index- chỉ mục và tìm kiếm. Dữ liệu tìm kiếm có thể là tập tin dạng PDF, Word hay HTML, Json,… hoặc dữ liệu trong các hệ quản trị dữ liệu như MS SQL, SQL server hay MySQL.
Lucene bắt đầu được phát triển trên ngôn ngữ java, đến nay thì được phát triển bằng nhiều ngôn ngũ như Perl, C++/C#, Python, Ruby, PHPĐược xây dựng và thiết kế theo hướng hướng đối tượng nên các API cũng được cung cấp theo dạng hướng đối tượng.

Mặc dù thiết kế và xây dựng ban đầu từ java nhưng hiện nay cũng đã có một số phiên bản cho các ngôn ngữ khác: .NET, C++, Perl.
Những sản phẩm sử dụng Lucene:
Beagle dùng một nhánh của Lucene phát triển trong C#, có tên gọi 25giay.vn làm chỉ mục.
– Docco dùng Lucene trong việc tìm kiếm trong máy tính cá nhân.
– CNET dùng Lucene để tìm kiếm danh sách thể loại sản phẩm. – LjFind dùng Lucene để tìm kiếm hơn 110.000.000 bài post ở LiveJournal. – Nutch là một máy tìm kiếm dùng Lucene.
– Red-Piranha cũng là một máy tìm kiếm khác dựa trên Lucene – Wikipedia dùng Lucene để tìm kiếm nội dung toàn bộ văn bản.
Xem thêm : Dịch vụ kế toán trong tiếng Anh là gì? Một số thuật ngữ kế toán tiếng Anh thông dụng
– Trình duyệt web Flock dùng Clucene, một phiên bản trong C++, để tìm kiếm toàn văn hoặc tìm kiếm lịch sử của trình duyệt.
– Ants P2P dùng Lucene trong lựa chọn tìm kiếm trong chương trình chia sẻ file khuyết danh của nó.
– Solr một máy chủ tìm kiếm nguồn mở dựa trên Lucene với XML/HTTP APIs, lưu trữ (cache), sao chép, và một giao diện web quản trị.
– LIRE – Lucene Image Retrieval Thư viện CBIR, dùng máy tìm kiếm Lucene.
Sự khác biệt giữa Lucene và Elasticsearch là gì
Elasticsearch là một máy chủ web dựa trên JSON , phân tán , được xây dựng trên Lucene. Mặc dù đó là Lucene, người đang thực hiện công việc thực tế bên dưới, Elasticsearch cung cấp cho chúng ta một lớp thuận tiện hơn Lucene. Mỗi phân đoạn được tạo ra trong Elasticsearch là một thể hiện Lucene riêng. Vì vậy, để tóm tắt
Elasticsearch được xây dựng trên Lucene và cung cấp API REST dựa trên JSON để tham khảo các tính năng của Lucene. Elasticsearch cung cấp một hệ thống phân tán trên đỉnh Lucene . Một hệ thống phân tán không phải là thứ mà Lucene nhận thức được hoặc được xây dựng cho. Elasticsearch cung cấp sự trừu tượng hóa của cấu trúc phân tán.
Elasticsearch cung cấp các tính năng hỗ trợ khác như nhóm luồng, hàng đợi, API giám sát nút / cụm, API giám sát dữ liệu, quản lý cụm, v.v.
Tính sẵn sàng cao: Elasticsearch được phân phối, để nó có thể quản lý sao chép dữ liệu, có nghĩa là có nhiều bản sao dữ liệu trong cụm của bạn. Điều này cho phép tính sẵn sàng cao.
DSL truy vấn mạnh mẽ : Elasticsearch cung cấp cho chúng tôi, giao diện JSON để đọc và viết các truy vấn trên Lucene. Nhờ Elasticsearch, bạn có thể viết các truy vấn phức tạp mà không cần biết cú pháp Lucene.
Schemaless (Schema-Free): Các trường (tên, cặp giá trị) schema không phải được xác định trước. Khi bạn lập chỉ mục dữ liệu, Elasticsearch có thể tự động tạo lược đồ khi chạy, như ma thuật.
Xem thêm : Amino là gì? Sử dụng amino trong tập được không ?
Lucene là một thư viện công cụ tìm kiếm . Bạn muốn sử dụng nó để xây dựng công cụ tìm kiếm của riêng mình: một đối thủ cạnh tranh mới của Elasticsearch hoặc Solr hoặc một cái gì đó hẹp cho trường hợp sử dụng của bạn (ví dụ: phân tích văn bản).
Elasticsearch là một công cụ tìm kiếm . Hầu hết mọi người sử dụng nó để tổng hợp nhật ký, tìm kiếm sản phẩm hoặc một biến thể của hai điều này (ví dụ: phân tích phương tiện truyền thông xã hội hoặc tìm người có liên quan cho một số tiêu chí tìm kiếm). Nó được xây dựng trên đỉnh Lucene, vì vậy nó phơi bày hầu hết (mặc dù không phải tất cả) các tính năng của nó . Nó cũng thêm rất nhiều trên đầu trang, đáng kể nhất:
Xem thêm: Tìm hiểu về Elasticsearch
- API REST
- truy vấn DSL
- hệ thống phân tán (shending, nhân rộng, quản lý cụm)
- khía cạnh / tập hợp
- các tính năng bổ sung cho việc sử dụng phổ biến (ví dụ: xử lý nhập ) và quản lý (API để theo dõi các số liệu liên quan , sao lưu và khôi phục, v.v.)

Chức năng của Lucence
Thành phần chức năng chính của Lucene bao gồm hai phần: Thành phần tạo chỉ mục và thành phần tìm kiếm. Đây là hai thành phần quan trọng cho một hệ thống tìm kiếm thông tin.
Thành phần Tạo chỉ mục: Bao gồm các chức năng xử lý và phân tích dữ liệu để đánh chỉ mục. Lucene cho phép thiết lập các trường thông tin cần thiết để đánh chỉ mục phục vụ cho thành phần tìm kiếm, các thư viện phục vụ đánh chỉ mục mà Lucene hỗ trợ.
Thành phần Tìm kiếm: bao gồm các phần chức năng xử lý tìm kiếm, trả về kết quả tìm kiếm cho người dùng, thông qua biên dịch và so khớp để lấy về kết quả tốt nhất.
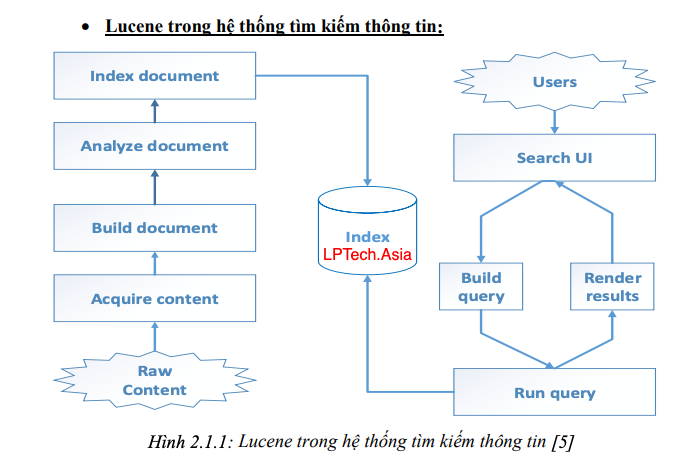
- Đánh chỉ mục (Index): Đầu tiên, Lucene giúp bạn phân loại chỉ mục, quản lý như các Document. Việc đánh chỉ mục được thực hiện qua những bước sau.
- Đầu tiên, thu thập dữ liệu (Acquire content), ở bước này thường là crawler hoặc spider để thu thập dữ liệu đánh chỉ mục.
- Tiếp theo là bước xây dựng tài liệu (Build document). Ở bước này thì dữ liệu thô thu nhập ở trên được chia thành các document và các trường text, nhưng các search engine vẫn chưa đánh chỉ mục luôn được mà cần được chuyển sang phân tích tài liệu.
- Phân tích tài liệu (Analyze document): Ở đây text được chia nhỏ thành các token, mỗi token được hiểu là một từ trong tài liệu. Document được xác định bởi dãy các token
- Bước cuối cùng là đánh chỉ mục. Lucene cung cấp API đầy đủ cho việc đánh chỉ mục trở nên dễ dàng hơn.
- Truy vấn (query): Khi người sử dụng gửi lên 1 submit thì hệ thống search engine cần phân tích thành câu query cho hệ thống có thể hiểu, bước này gọi là (Build query). Lucene cung cấp gói QueryParser để biến câu truy vấn của người sử dụng thành câu query của hệ thống.Truy vấn có thể là các toán tử boolean hoặc các phép toán liên quan, hoặc tổng hợp, phân tích,…
- Tìm kiếm (search): Là quá trình tra cứu và tìm ra kết quả phù hợp với câu truy vấn của người sử dụng và đưa ra kết quả. Ở đây thường query theo 3 mô hình: Mô hình toán tử Boolean, mô hình vector, mô hình xác suất. Những mô hình này đã được giới thiệu trong bài truy vấn thông tin (IR).
- Display: Render các kết quả tìm kiếm sắp xếp theo thứ tự phù hợp và hiển thị cho người sử dụng. Ở đây, kết thúc một phiên tìm kiếm.
Sức mạnh của Lucene
Không phải dễ dàng mà người ta nói : Lucene có thể giúp bạn phát triển công cụ tìm kiếm “giống Google” với năng lực tìm kiếm mạnh mẽ và linh hoạ.Bởi những ưu điểm vượt bậc của bộ thư viện này hỗ trợ cho việc lập index và tìm kiếm

Hiện nay tồn tại rất nhiều hệ quản trị hỗ trợ cho kỷ thuật tìm kiếm Full Text, trong đó nổi lên 2 hệ quản trị lớn đó là MySQL và OracleTại sao lựa chọn Lucene thay vì hệ quản trị CSDL như MySQL cho yêu cầu bài toán bởi vì :
- Khác với MySQL, dữ liệu được index phải được lưu trữ trong database, trong khi đó Lucene chỉ tạo chỉ mục trên dữ liệu hiện có. Bằng cách này, Lucene có thể tạo chỉ mục cho dữ liệu lưu trữ trong database, trong các thư mục của hệ thống tập tin. Hơn thế nữa, với việc dùng các plug-in về parsing, Lucene có thể đánh chỉ mục cho các tập tin pdf, html, MS Word, etc.
- Câu truy vấn của MySQL bị giới hạn bởi cú pháp của SQL query, trong khi câu truy vấn của Lucene gần với các hệ thống information retrieval hơn. Với Lucene, bạn có thể dùng proximity search, fuzzy search, wildcard search và quan trọng nhất là term boosting có thể giúp rank các kết quả trả về theo mức độ liên quan (relevancy).
- Tốc độ của Lucene tốt hơn so với MySQL trong trường hợp dữ liệu lớn.Ngoài ra một hệ quản trị cơ sở có hỗ trợ kỷ thuật full text nổi tiếng nữa đó là Oracle Enterprise.Và qua một số thử nghiệm trên cùng hệ thống máy tính và cùng 1 số lượng tài liệu có được kết quả như sau :
- Về tốc độ – Lucene là nhanh hơn:
- Máy chủ Oracle bổ sung thêm giấy phép CPU DB, mà là đến nay đắt hơn so với máy chủ Lucene ứng dụng rẻ hơn và bộ nhớ nhiều hơn
- Chỉ số kích thước – chỉ số Lucene nhỏ
- Tính điểm thuật toán: Không thể tùy chỉnh với văn bản Oracle, còn Lucene có thể
- Tiến bộ Lucene : bổ sung thêm một số trường (term) Fuzzy, Synonym, Near tìm kiếm nhanh lên đáng kể
- Hiện nay rất nhiều ứng dụng hay website nổi tiếng sử dụng Lucene làm thư viện tìm kiếm như là Thư viện Wiki,HP, eclipe.
Trong series này tôi sẽ viết các bài khác gồm:
- Kibana là gì? Tìm hiểu về Kibana và sử dụng một cách hiệu quả
- Grafana là gì ? Hướng dẫn cài đặt Grafana cho DevOps tối ưu hiệu năng
- MongoDB là gì? Cách cài đặt và tìm hiểu cơ bản về MongoDB
- Redis là gì? Tại sao cần hiểu và sử dụng Redis để tối ưu hiệu xuất
- Apache Solr: Hướng dẫn cài đặt và cách sử dụng Apache Solr
- Elasticsearch là gì
- Logstash là gì? Cài đặt sử dụng và làm chủ Logstash trong 1 bài viết
Nguồn: https://25giay.vn
Danh mục: Hỏi Đáp